Grafico della conoscenza
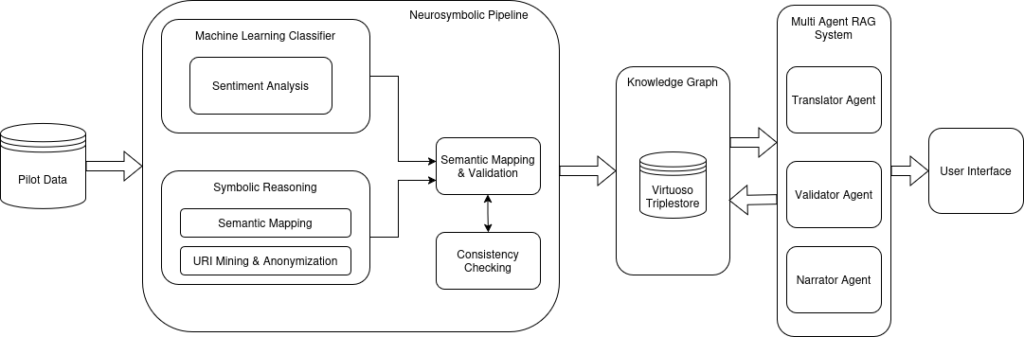
Il Knowledge Graph AI4Deliberation modella le consultazioni pubbliche come una gerarchia strutturata IBIS (Issue-Based Information System): Le consultazioni contengono articoli (disposizioni legislative) che accettano le posizioni dei cittadini (emendamenti proposti), ciascuno sostenuto da argomentazioni. Le analisi estratte tramite LLM da diversi set di dati di consultazione vengono convertite tramite una pipeline ETL in triple RDF memorizzate in un triplo negozio Virtuoso. Un servizio RAG multi-agente (Translator → Validator → Narrator) risponde alle domande del linguaggio naturale creando ed eseguendo query SPARQL su questo grafico.
Come funziona Grafico della conoscenza;
1. Dati
La fonte sono i dati di consultazione greci, che consistono in diversi database SQLite, uno per articolo legislativo. Ogni database contiene commenti dei cittadini elaborati in anticipo da uno strumento, che ha estratto un JSON strutturato da ogni commento: un elenco dei posti (emendamenti proposti con emendamento _type: aggiunta, rimozione, modifica o suggerimento) e argomenti per posizione (ciascuno con polarità: positivo, negativo o neutro).
2. Conduttura di ETL
Il gasdotto viene eseguito in due fasi:
Esportazione: Legge ogni database SQLite e analizza JSON. Mantiene la struttura nidificata completa: consultazione → articolo → commento → posizioni → argomenti. I metadati degli articoli e delle consultazioni (titoli, ministero, date) sono ricercati dalla principale fonte di dati della consultazione.
Trasformazione: Converte i dati estratti in triadi RDF utilizzando l'ontologia IBIS:
- Ogni Consultazione e Articolo diventa un ibis:Issue hub
- ibis:questions collega una consultazione a ciascuno dei suoi articoli
- Ogni posizione esportata diventa ibis:Position con ibis:respondsTo mostrando nel suo articolo
- Articoli con emendamento _type: la rimozione o la modifica acquisiscono anche ibis:objectsTo → Articolo
- Ogni argomento diventa ibis:Argument con ibis:supports o ibis:objectsPer mostrare nella sua posizione
- I commenti iniziali dei cittadini sono mantenuti come og:Nodi di commento collegati alle posizioni tramite og:extractedFrom
3. Salva il grafico della conoscenza
La pipeline serializza il grafico in formato file ttl. Questo file Turtle viene caricato in un triplo store Virtuoso, che espone un endpoint SPARQL 1.1.
4. Servizio RAG
Un servizio FastAPI racchiude una pipeline di tre agenti alimentati da LLM:
- Agente del traduttore: Prende la domanda del linguaggio naturale dell'utente (insieme alla cronologia delle conversazioni) e genera una query SPARQL seguendo le regole di transito IBIS.
- Agente validatore: Controlla lo SPARQL generato per la correttezza strutturale, come prefissi validi, proprietà valide, attraversamento multi-step corretto, senza false predicazioni, e lo approva o restituisce una correzione.
- Agente Narratore: Esegue la query convalidata in Virtuoso, riceve le linee di risultato grezze e compone una risposta coerente in lingua naturale in greco o inglese a seconda della domanda.
5. Interazione dell'utente
Gli utenti inviano una domanda (con cronologia chat opzionale) all'endpoint. I tre agenti vengono eseguiti in sequenza. Se la query non restituisce i risultati, Narratore lo afferma chiaramente invece di inventare una risposta. Le conversazioni multi-round sono supportate dal trasferimento di coppie precedenti (domanda, risposta) con ogni richiesta.